SQL 的基本使用概念简介
查询不重复的记录
SELECT 指令让我们能够读取表格中一个或数个栏位的所有资料。这将把所有的资料都抓出,无论资料值有无重复。在资料处理中,我们会经常碰到需要找出表格内的不同资料值的情况。换句话说,我们需要知道这个表格/栏位内有哪些不同的值,而每个值出现的次数并不重要。这要如何达成呢?在 SQL 中,这是很容易做到的。我们只要在 SELECT 后加上一个 DISTINCT 就可以了。DISTINCT 的语法如下:
SELECT DISTINCT "栏位名"
FROM "表格名";
如果指定多列,则同时根据多列的值里去重,如 (1, 1) 与 (1, 2) 为不重复的数据。
多个复杂查询条件
WHERE 的多个复杂条件是由二或多个简单条件通过 AND 或是 OR 的连接而成。一个 SQL 语句中可以有无限多个简单条件的存在。
复杂条件的语法如下:
SELECT "栏位名"
FROM "表格名"
WHERE "简单条件"
{[AND|OR] "简单条件"}+;
{}+ 代表 {} 之内的情况会发生一或多次。在这里的意思就是 AND 加简单条件及 OR 加简单条件的情况可以发生一或多次。另外,我们可以用 () 来代表条件的先后次序。
还可以使用 NOT 来否定条件,如:
SELECT * FROM user WHERE NOT name="huoty";
表示获取 user 表中 name 不为 huoty 的所有行,其余 != 效果相同。
为一个条件匹配多个可能的值
在 SQL 中,在两个情况下会用到 IN 这个指令;这里先说 与 WHERE 有关的那一个情况。在这个用法下,我们事先已知道至少一个我们需要的值,而我们将这些知道的值都放入 IN 这个子句。 IN 指令的 语法为下:
SELECT "栏位名"
FROM "表格名"
WHERE "栏位名" IN ('值一', '值二', ...);
在括弧内可以有一或多个值,而不同值之间由逗点分开。值可以是数目或是文字。若在括弧内只有一个值,那这个子句就等于:
WHERE "栏位名" = '值一'
限制查询的范围
IN 这个指令可以让我们依照一或数个不连续 (discrete) 的值的限制之内抓出数据库中的值,而 BETWEEN 则是让我们可以运用一个范围 (range) 内抓出数据库中的值。BETWEEN 这个子句的语法如下:
SELECT "栏位名"
FROM " 表格名"
WHERE "栏位名" BETWEEN '值一' AND '值二';
这将选出栏位值包含在值一及值二之间的记录。
模糊匹配的查询条件
LIKE 是另一个在 WHERE 子句中会用到的指令。基本上,LIKE 能让我们依据一个套式 (pattern) 来找出我们要的资料。相对来说,在运用 IN 的时候,我们完全地知道我们需要的条件;在运用 BETWEEN 的时候,我们则是列出一个范围。 LIKE 的语法如下:
SELECT "栏位名"
FROM "表格名"
WHERE "栏位名" LIKE {套式};
{套式} 经常包括通配符 (wildcard),包括 % 匹配任意数量的任意字符,_ 匹配单个字符,[] 匹配给定字符集中的任意一个字符,[^] 匹配除给定字符集意外的任意单个字符。 以下是几个例子:
- ‘A_Z’: 所有以 ‘A’ 起头,另一个任何值的字原,且以 ‘Z’ 为结尾的字串。 ‘ABZ’ 和 ‘A2Z’ 都符合这一个模式,而 ‘AKKZ’ 并不符合 (因为在 A 和 Z 之间有两个字原,而不是一个字原)。
- ‘ABC%’: 所有以 ‘ABC’ 起头的字串。举例来说,’ABCD’ 和 ‘ABCABC’ 都符合这个套式。
- ‘%XYZ’: 所有以 ‘XYZ’ 结尾的字串。举例来说,’WXYZ’ 和 ‘ZZXYZ’ 都符合这个套式。
- ‘%AN%’: 所有含有 ‘AN’ 这个套式的字串。举例来说, ‘LOS ANGELES’ 和 ‘SAN FRANCISCO’ 都符合这个套式。
- ‘[JM]%’: 所有以 J 或者 M 开头的字串。
- ’[^JM]%’: 所有不以 J 或者 M 开头的字串。
限制返回的行数
SELECT 默认返回匹配的所有行,而有时返回的结果可能会很大,太大的数据量给传输带来了困难。SQL 的 LIMIT 指令限制返回的行数,其返回最前面的指定行数据。LIMIT 语法为:
SELECT "栏位名"
FROM "表格名"
LIMIT "行数"
还可以用 OFFSET 指令指定起始行的位置:
SELECT "栏位名"
FROM "表格名"
LIMIT "行数" OFFSET "起始行"
排序查询的记录
ORDER BY 这个指令用来将查询的值由小往大 (ascending) 或是由大往小 (descending) 进行排序, ORDER BY 的语法如下:
SELECT "栏位名"
FROM "表格名"
[WHERE "条件"]
ORDER BY "栏位名" [ASC, DESC];
[ ] 代表 WHERE 语句是可选的。不过,如果 WHERE 子句存在的话,它是在 ORDER BY 子句之前。ASC 代表结果会以由小往大的顺序列出,而 DESC 代表结果会以由大往小的顺序列出。如果两者皆没有被写出的话,那我们就会用 ASC。
我们可以照好几个不同的栏位来排顺序。在这个情况下,ORDER BY 子句的语法如下(假设有两个栏位):
ORDER BY "栏位一", "栏位二"
ORDER BY "栏位一" [ASC, DESC], "栏位二" [ASC, DESC]
若我们对这两个栏位都选择由小往大的话,那这个子句就会造成结果是依据 “栏位一” 由小往大排。若有好几笔资料 “栏位一” 的值相等,那这几笔资料就依据 “栏位二” 由小往大排。
使用函数
既然数据库中有许多资料都是已数字的型态存在,一个很重要的用途就是要能够对这些数字做一些运算,例如将它们总合起来,或是找出它们的平均值。SQL 有提供一些这一类的函数。它们是:
- AVG (平均)
- COUNT (计数)
- MAX (最大值)
- MIN (最小值)
- SUM (总合)
运用函数的语法是:
SELECT "函数名"("栏位名")
FROM "表格名";
由于 COUNT 的使用广泛,在这里特别提出来讨论。基本上,COUNT 让我们能够数出在表格中有多少笔资料被选出来。它的语法是:
SELECT COUNT("栏位名")
FROM "表格名";
GROUP BY 语句
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。下面用一个实例来说明,以下为一个数据表:
| O_Id | OrderDate | OrderPrice | Customer |
|---|---|---|---|
| 1 | 2008/12/29 | 1000 | Bush |
| 2 | 2008/11/23 | 1600 | Carter |
| 3 | 2008/10/05 | 700 | Bush |
| 4 | 2008/09/28 | 300 | Bush |
| 5 | 2008/08/06 | 2000 | Adams |
| 6 | 2008/07/21 | 100 | Carter |
现在,我们希望查找每个客户的总金额(总订单)。我们想要使用 GROUP BY 语句对客户进行组合。我们使用下列 SQL 语句:
SELECT Customer,SUM(OrderPrice) FROM Orders
GROUP BY Customer
结果集类似这样:
| Customer | SUM(OrderPrice) |
|---|---|
| Bush | 2000 |
| Carter | 1700 |
| Adams | 2000 |
HAVING 子句:
HAVING 语句允许指定条件来过滤将出现最终结果中的分组结果。 WHERE 子句在所选列上设置条件,而 HAVING 子句则在由 GROUP BY 子句创建的分组上设置条件。HAVING 子句必须放在 GROUP BY 子句之后,必须放在 ORDER BY 子句之前。
HAVING 的语法如下:
SELECT "栏位1", SUM("栏位2")
FROM "表格名"
[WHERE "条件"]
GROUP BY "栏位1"
HAVING (函数条件);
ORDER BY "栏位名" [ASC, DESC];
总结一下 SELECT 字句的顺序:
| 字句 | 说明 | 是否必须 |
|---|---|---|
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅从表中获取数据时必须 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅需要将数据分组时必须 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 结果排序 | 否 |
SQL 别名(alias)
SQL 可以对表或列进行重命名。使用表的别名,是指在一个特定的 SQL 语句重命名一个表。重命名是一个临时的变化,并在数据库中实际的表的名称不会改变。列的别名是用来重命名表中的列一个特定的 SQL 查询的目的。
表别名的基本语法如下:
SELECT column1, column2....
FROM table_name AS alias_name
WHERE [condition];
列别名的基本语法如下:
SELECT column_name AS alias_name
FROM table_name
WHERE [condition];
其中,AS 可以省略,直接用空格代替,即可以用 “表名或者列名 别名” 的方式重命名。
SQL Join 类型
在 SQL 连接中有不同的类型可用:
- INNER JOIN: 内连接,返回记录当两个表有匹配。
- LEFT JOIN: 左连接,返回左表中所有的行,即使右表中没有匹配。
- RIGHT JOIN: 右连接,返回右表中所有的行,即使有在左表中没有匹配。
- FULL JOIN: 全连接,返回表中匹配的所有行。
- SELF JOIN: 自连接,是用来连接表本身,如果表有两张表,暂时改名至少在一个表中的SQL语句。
- CROSS JOIN: 交叉连接,返回来自两个或更多个联接的表的记录的集合的笛卡尔乘积。
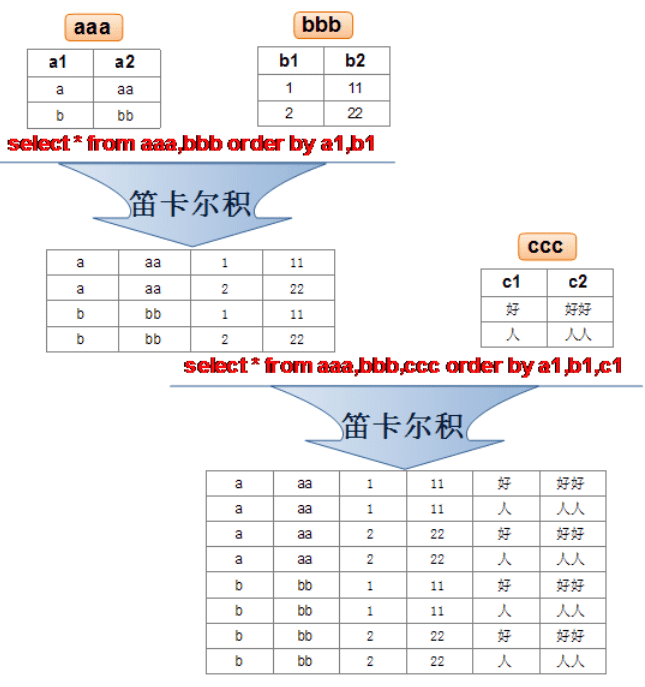
内连接中如果不指定过滤条件,则会返回多表的 笛卡尔积 结果:
根据连接查询返回的结果,可将连接类型分为 3 类:
- 内连接(inner join)
- 外连接(outer join):包括 LEFT JOIN 和 RIGHT JOIN
- 交叉连接(cross join)
内连接(通常也要等值连接)有两种语法:
SELECT a.c1, b.c1 FROM t1 AS a, t2 AS b WHERE a.id = b.aid
SELECT a.c1, b.c1 FROM t1 AS a INNER JOIN t2 AS b ON a.id = b.aid
左连接和右连接统称为外连接,其语法为:
SELECT a.c1, b.c1 FROM t1 AS a LEFT JOIN t2 AS b ON a.id = b.aid
SELECT a.c1, b.c1 FROM t1 AS a RIGHT JOIN t2 AS b ON a.id = b.aid
自连接是指表自己与自己连接,其也是内连接的一种,通常使用 as 语句将同一个表作两个别名,自连接通常用来优化一个 SQL 中的子查询。其语法为:
SELECT a.c1, b.c2 FROM t AS a, t AS b WHERE a.c1 = b.c2 AND a.c3 = 'xxx'
子查询(Subquery)
我们可以在一个 SQL 语句中放入另一个 SQL 语句。当我们在 WHERE 子句或 HAVING 子句中插入另一个 SQL 语句时,我们就有一个 subquery 的架构。 Subquery 的作用是什么呢?第一,它可以被用来连接表格。另外,有的时候 subquery 是唯一能够连接两个表格的方式。
Subquery 的语法如下:
SELECT "栏位1"
FROM "表格"
WHERE "栏位2" [比较运算符]
(SELECT "栏位1"
FROM "表格"
WHERE "条件");
[比较运算符] 可以是相等的运算符,例如 =, >, <, >=, <=, 这也可以是一个对文字的运算符,例如 “LIKE”。
UNION语句
UNION 指令的目的是将两个 SQL 语句的结果合并起来。从这个角度来看, UNION 跟 JOIN 有些许类似,因为这两个指令都可以由多个表格中撷取资料。 UNION 的一个限制是两个 SQL 语句所产生的栏位需要是同样的资料种类。另外,当我们用 UNION 这个指令时,我们只会看到不同的资料值 (类似 SELECT DISTINCT)。
UNION 的语法如下:
[SQL 语句 1]
UNION
[SQL 语句 2];
UNION ALL 这个指令的目的也是要将两个 SQL 语句的结果合并在一起。 UNION ALL 和 UNION 不同之处在于 UNION ALL 会将每一笔符合条件的资料都列出来,无论资料值有无重复。
UNION ALL 的语法如下:
[SQL 语句 1]
UNION ALL
[SQL 语句 2];
INTERSECT 语句
和 UNION 指令类似,INTERSECT 也是对两个 SQL 语句所产生的结果做处理的。不同的地方是, UNION 基本上是一个 OR (如果这个值存在于第一句或是第二句,它就会被选出),而 INTERSECT 则比较像 AND ( 这个值要存在于第一句和第二句才会被选出)。UNION 是联集,而 INTERSECT 是交集。
INTERSECT 的语法如下:
[SQL语句 1]
INTERSECT
[SQL语句 2];
MINUS 语句:
MINUS 指令是运用在两个 SQL 语句上。它先找出第一个 SQL 语句所产生的结果,然后看这些结果有没有在第二个 SQL 语句的结果中。如果有的话,那这一笔资料就被去除,而不会在最后的结果中出现。如果第二个 SQL 语句所产生的结果并没有存在于第一个 SQL 语句所产生的结果内,那这笔资料就被抛弃。
MINUS 的语法如下:
[SQL 语句 1]
MINUS
[SQL 语句 2];
CONCAT 函数
有的时候,我们有需要将由不同栏位获得的资料串连在一起。每一种数据库都有提供方法来达到这个目的:
- MySQL: CONCAT( )
-
Oracle: CONCAT( ), - SQL Server: +
CONCAT( ) 的语法如下:
CONCAT (字串1, 字串2, 字串3, ...)
| 将字串1、字串2、字串3,等字串连在一起。请注意,Oracle 的 CONCAT( ) 只允许两个参数;换言之,一次只能将两个字串串连起来。不过,在Oracle中,我们可以用 ‘ | ’ 来一次串连多个字串。 |
来看几个例子。假设我们有以下的表格:
| Geography | 表格 |
|---|---|
| region_name | store_name |
| East | Boston |
| East | New York |
| West | Los Angeles |
| West | San Diego |
例子1:
MySQL/Oracle:
SELECT CONCAT (Region_Name, Store_Name) FROM Geography
WHERE Store_Name = 'Boston';
结果:
'EastBoston'
例子2:
Oracle:
SELECT Region_Name || ' ' || Store_Name FROM Geography
WHERE Store_Name = 'Boston';
结果:
'East Boston'
例子3:
SQL Server:
SELECT Region_Name + ' ' + Store_Name FROM Geography
WHERE Store_Name = 'Boston';
结果:
'East Boston'
曾、删、改操作
INSERT INTO 语句用于向表中插入新记录,其语法格式为:
-- 不用指定列名,当 value 必须提供所有列的值
INSERT INTO table_name
VALUES (value1,value2,value3,...);
-- 显式指定列名
INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...);
DELETE 语句用于删除表中的行,其语法格式为:
DELETE FROM table_name WHERE some_column=some_value;
-- 表连接时
DELETE t1 FROM table1 as t1, table2 as t2
WHERE t1.some_column=t2.some.column and t1.some_column=some_value;
UPDATE 语句用于更新表中已存在的记录,其语法格式为:
UPDATE table_name
SET column1=value1, column2=value2, ...
WHERE some_column=some_value;
CASE WHEN 语句
CASE WHEN 语句是 SQL 中的控制语句,类似于其他编程语言中的 switch case 语句。其语法格式为:
-- 简单模式
CASE value-expression
WHEN [ constant | NULL ] THEN statement-list ...
[ WHEN [ constant | NULL ] THEN statement-list ] ...
[ ELSE statement-list ]
END [ CASE ]
-- 搜索模式
CASE
WHEN [ search-condition | NULL] THEN statement-list ...
[ WHEN [ search-condition | NULL] THEN statement-list ] ...
[ ELSE statement-list ]
END [ CASE ]
简单的示例:
-- 简单 case 函数
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
-- case 搜索函数
CASE
WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
CASE WHEN 语句还可以用于更新语句中。如对某公司当前工资为 1 万以上的员工降薪 10%,对当前工资低于 1 万的员工,加薪 20%,更新语句为:
UPDATE Salaries
SET salary = CASE WHEN salary >= 10000 THEN salary * 0.9
WHEN salary < 280000 THEN salary * 1.2
ELSE salary END;
SQL UNIQUE 约束
UNIQUE 约束唯一标识数据库表中的每条记录。UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。PRIMARY KEY 拥有自动定义的 UNIQUE 约束。请注意,每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
常用 SQL 函数
注:以下列列举函数尽在 MySQL 环境下测试通过。
字符串函数:
| 函数名称 | 作 用 |
|---|---|
| LENGTH | 计算字符串长度函数,返回字符串的字节长度 |
| CONCAT | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 |
| INSERT | 替换字符串函数 |
| LOWER | 将字符串中的字母转换为小写 |
| UPPER | 将字符串中的字母转换为大写 |
| LEFT | 从左侧字截取符串,返回字符串左边的若干个字符 |
| RIGHT | 从右侧字截取符串,返回字符串右边的若干个字符 |
| TRIM | 删除字符串左右两侧的空格 |
| REPLACE | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING | 截取字符串,返回从指定位置开始的指定长度的字符换 |
| REVERSE | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
日期和时间函数:
| 函数名称 | 作 用 |
|---|---|
| CURDATE 和 CURRENT_DATE | 两个函数作用相同,返回当前系统的日期值 |
| CURTIME 和 CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW 和 SYSDATE | 两个函数作用相同,返回当前系统的日期和时间值 |
| UNIX_TIMESTAMP | 获取UNIX时间戳函数,返回一个以 UNIX 时间戳为基础的无符号整数 |
| FROM_UNIXTIME | 将 UNIX 时间戳转换为时间格式,与UNIX_TIMESTAMP互为反函数 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定日期中的月份英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1〜53 |
| DAYOFYEAR | 获取指定曰期是一年中的第几天,返回值范围是1~366 |
| DAYOFMONTH | 获取指定日期是一个月中是第几天,返回值范围是1~31 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| TIME_TO_SEC | 将时间参数转换为秒数 |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| DATE_ADD 和 ADDDATE | 两个函数功能相同,都是向日期添加指定的时间间隔 |
| DATE_SUB 和 SUBDATE | 两个函数功能相同,都是向日期减去指定的时间间隔 |
| ADDTIME | 时间加法运算,在原始时间上添加指定的时间 |
| SUBTIME | 时间减法运算,在原始时间上减去指定的时间 |
| DATEDIFF | 获取两个日期之间间隔,返回参数 1 减去参数 2 的值 |
| DATE_FORMAT | 格式化指定的日期,根据参数返回指定格式的值 |
| WEEKDAY | 获取指定日期在一周内的对应的工作日索引 |
MySQL 聚合函数:
| 函数名称 | 作用 |
|---|---|
| MAX | 查询指定列的最大值 |
| MIN | 查询指定列的最小值 |
| COUNT | 统计查询结果的行数 |
| SUM | 求和,返回指定列的总和 |
| AVG | 求平均值,返回指定列数据的平均值 |
数值型函数:
| 函数名称 | 作 用 |
|---|---|
| ABS | 求绝对值 |
| SQRT | 求二次方根 |
| MOD | 求余数 |
| CEIL 和 CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0~1之间的随机数,传入整数参数是,用来产生重复序列 |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号 |
| POW 和 POWER | 两个函数的功能相同,都是所传参数的次方的结果值 |
| SIN | 求正弦值 |
| ASIN | 求反正弦值,与函数 SIN 互为反函数 |
| COS | 求余弦值 |
| ACOS | 求反余弦值,与函数 COS 互为反函数 |
| TAN | 求正切值 |
| ATAN | 求反正切值,与函数 TAN 互为反函数 |
| COT | 求余切值 |
